
Her er en artikel skrevet af Greg Chapman og offentliggjort på WUWT. Chapman har arbejdet med computermodeller, men ikke inden for klimaet. Han står således som en ekspert med et syn på sagen ude fra. Det følgende er en lettere forkortet oversættelse:
Klodens undergang pga. global opvarmning er blevet forudset flere gange, end klima-aktivisten Leo DiCaprio har rejst med privatfly. Men hvor kommer de forudsigelser fra? Hvis I tror, at de bare er beregnet ud fra den simple velkendte sammenhæng mellem CO2 og absorption fra solenergiens spektrum, så ville I kun forvente en temperaturstigning på ca. 0,5 grader celsius fra det førindustrielle niveau ved en fordobling af CO2-niveauet, pga. den logaritmiske sammenhæng mellem de to.
De løbske 3-6 oC eller endnu højere forudsigelser fra modellerne afhænger af forstærkende feedbacks fra mange andre faktorer, inkl. vanddamp (den vigtigste drivhusgas), albedoen (den del af solenergien, der kastes tilbage som synligt lys – hvor mere is eller skyer giver større tilbagekastning osv.) og partikler i atmosfæren (de såkaldte aerosoler), bare for at nævne nogle få blandt dem, der kunne forstærke den beskedne effekt af CO2. På grund af denne komplicerede sammenhæng, er klimamodeller den eneste måde, hvorpå man kan lave forudsigelser, fordi direkte beregninger er umulige.
Hvordan virker klimamodeller?
For at kunne simulere Jorden i en computermodel, må man skabe et gitterværk af celler fra havenes bund til toppen af atmosfæren, se fig. 1. Inde i hver celle er egenskaberne, som f.eks. temperatur, tryk, indhold af partikler, væske og damp ensartede over det hele.
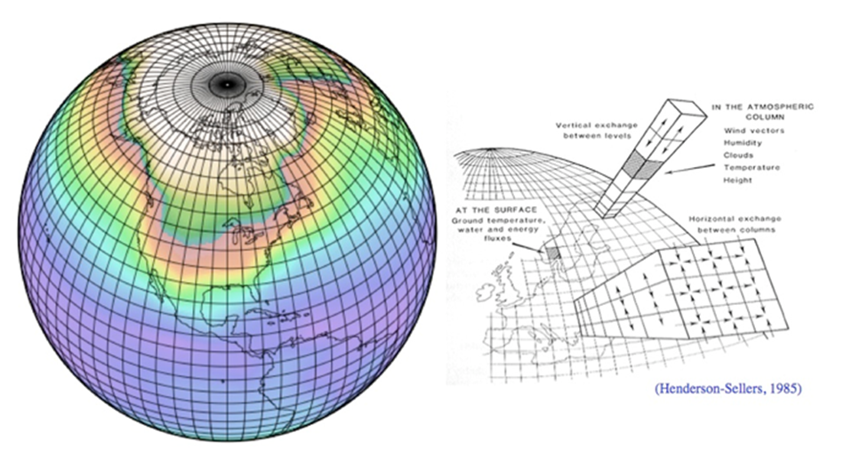
Cellernes størrelse varierer fra den ene model til den anden og fra celle til celle i den samme model. Ideelt set skulle cellerne være så små som muligt, da egenskaberne varierer kontinuerligt i den virkelige Verden, men størrelsen er begrænset af computernes regnekraft. Typisk er cellerne omkring 100 x 100 km, selvom der kan være store variationer i atmosfæren inden for de afstande, men det er nødvendigt at vælge en gennemsnitsværdi for hele cellen. Det giver en uundgåelig fejl i modellerne allerede før, de begynder at køre.
Antallet af celler i en model varierer, men er er typisk omkring to millioner.
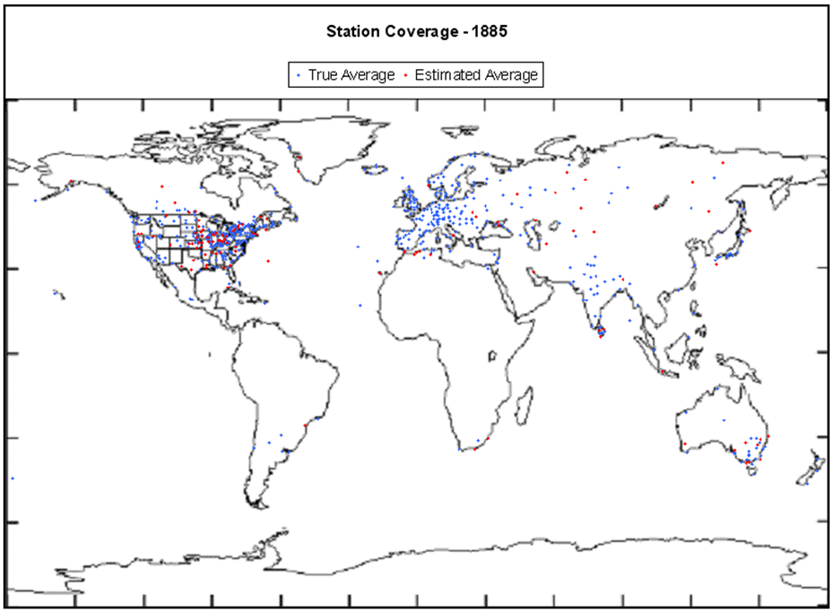
Når først gitteret er konstrueret, skal de forskellige egenskaber i hver celle fastlægges. Nu er der jo ikke 2 millioner målestationer i atmosfæren eller havet. P.t. har vi omkring 10.000 målepunkter globalt (vejrstationer på land, balloner og bøjer ude i havet), plus at vi fra 1978 også har data fra satellitterne, men historisk set er dækningen meget lille. Resultatet er, at når vi skal fastlægge startbetingelserne for en klimamodel, der begynder med et tidspunkt for 150 år siden, jf. fig. 2, er der næsten ingen data til rådighed for det meste af landoverfladerne, polerne og havene, og ingenting oppe i atmosfæren eller under havoverfladen. Det burde betragtes som en alvorlig bekymring.
Når først modellen har fået tilført startbetingelserne, begynder den at køre fremad i tid, et trin ad gangen. I hvert trin, for hver celle, bliver dens tilstand sammenlignet med nabocellernes. Hvis f.eks. en celle har et højere tryk end naboen, vil væske eller gas strømme fra cellen over til naboen. Hvis en celle er varmere, vil den opvarme nabocellerne og selv blive afkølet. Det kan få is til at smelte eller vand til at fordampe, men fordampningen har en afkølende effekt. Hvis is ved polerne smelter, bliver der tilbagekastet mindre sollys, og der bliver mere opvarmning. Partikler i cellen kan medføre opvarmning eller afkøling og mere eller mindre regn.
Forøget regnmængde kan få plantevæksten til at stige, det samme gælder en stigning i CO2-indholdet. Det vil ændre på overfladens albedo (tilbagekastning af lys) og fugtighed. Højere temperaturer giver større fordampning fra havene, hvilket afkøler vandet og giver et tættere skydække. Klimamodeller kan ikke simulere skyer pga. gitterets grove masker, og de kan ikke fortælle, om skyerne fører til en højere eller lavere overfladetemperatur, da det afhænger af hvilken type sky, der er tale om.
Det er kompliceret! Selvfølgeligt sker det hele i 3 dimensioner og hver celle modtager meget feedback fra alle sider, som så skal beregnes i hvert tidstrin, se fig. 3.
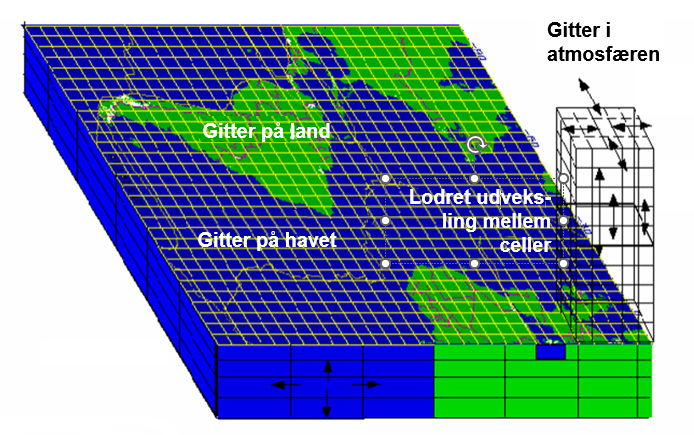
I tid kan trinene være så korte som en halv time. Husk at det punkt, hvor dag bliver til nat på jordoverfladen, bevæger sig med en hastighed på ca. 1700 km pr. time ved Ækvator, så selv tidstrin på en halv time giver yderligere fejl i beregningerne, men igen er computerens regnekraft den begrænsende faktor.
Imens ændringerne i tryk og temperatur mellem cellerne bliver beregnet i overensstemmelse med termodynamikkens love, er der mange andre ændringer, der ikke bliver beregnet. Her bruger man i stedet fastlagte parametre. F.eks. varierer albedoen for isdækkede områder, junglen i Amazonas, Saharas ørkener, havene, skydækkede arealer og alle områder ind i mellem. Bidragene herfra til cellerne bliver bare tildelt faste værdier, og deres indflydelse på andre ting fremgår af tabeller, der er udarbejdet forinden. De bliver ikke beregnet. Parametre bliver også benyttet til indflydelsen af skyer og partikler på temperaturen og mængden af nedbør.
Skydannelse afhænger af processer, der foregår i millimeter-skala og er helt umulige at simulere med modeller.
Når alle disse tilnærmede værdier kombineres med hvert eneste trin i tiden, opstår der flere fejl og med halvtimes-trin over 150 år er det over 2,6 millioner trin i alt! Desværre retter disse fejl ikke sig selv. I stedet vil disse afvigelse hobe sig op i løbet af modelkørslen, men der er en teknik, som klimamodellernes ophav bruger til at tackle det problem, den kommer vi tilbage til.
Igangsætning af modellen
Efter man har bygget en computermodel færdig, vil der i alle tilfælde være brug for en proces, hvor hver celle får tildelt startværdier, og man tjekker, at disse værdier ikke er i modstrid med hinanden men fysisk giver mening som naboceller.
Med klimamodellerne har vi to problemer med tildelingen af startværdier. For det første har vi meget lidt viden om klimaet i starttidspunktet, hvad det så måtte vælges til. For det andet er virkeligheden på starttidspunktet ikke i nogen ligevægtssituation. Til tiden nul kan der f.eks. være en snestorm i Sibirien, en tyfon i Japan, monsunregn i Mumbai og en hedebølge i Australien, for ikke at tale om det tilfældige vulkanudbrud. Alle disse tildragelser kunne være væk få dage senere.
Der er aldrig noget tidspunkt i klimaet hvor det er i ligevægt, så det er umuligt at efterkontrollere startbetingelserne.
Kontrol mod historien
Hvis det system, der simuleres med computeren har været i gang gennem nogen tid – den historiske periode – kan man bruge målte data fra virkeligheden i den første del af perioden til at indjustere modellen og derpå se, hvordan modellen klarer sig i den efterfølgende del. Dermed lader man computeren ”forudsige”, hvad der sker i denne anden del af den historiske periode. I modstrid med alle andre modelbyggere kalder klimaforskerne denne anden periode for retroanalysen (eng. hindcasting) for ligesom at understrege, at de ikke manipulerer med modellens parametre her for at få den til at stemme overens med virkeligheden.
Klimamodellerne har mange svagheder, f.eks. store cellestørrelser, ufuldstændige data af tvivlsom kvalitet i de tidligere år og fysiske fænomener, der driver klimaet, men som kun er dårligt forstået og alligevel bruges til fastlæggelse af parametrene. Alligevel er teorien, at det er muligt at indjustere modellen på basis af retroanalysen, således at alle disse svagheder bliver løst inden for den usikkerhed, der ligger i parametrene.
Mens det er rigtigt, at man kan justere modellen til at opnå en rimelig overensstemmelse med i hvert fald nogle af de historiske tildragelser, så vil overensstemmelsen ikke give det samme resultat fra gang til gang.
I klimamodellerne er der hundredvis af parametre, der kan stilles på, for at få overensstemmelse med de faktiske historiske data. Det betyder, at der er næsten uendeligt mange måder, hvorpå man kan opnå det resultat. Ja, mange af resultaterne er naturligvis i modstrid med basale fysiske lovmæssigheder og må kasseres, men med de store usikkerheder, der er på parametrene, er der bare ved at justere inden for disse usikkerheder stribevis af mulige løsninger.
Greg Chapman bruger her en analogi med et haglgevær, der affyres. Haglene bevæger sig ikke kun fremad gennem løbet, men de har også små sidelæns bevægelser, og så snart de forlader geværets munding, begynder de at sprede sig i forskellige retninger.
Ligesom med haglene begynder de forskellige klimamodeller at bevæge sig i forskellige retninger lige så snart de slippes fri fra den første del af den historiske periode, hvor de blev holdt på sporet af justeringerne. Men så snart de slipper væk herfra spredes de hurtigt, som vist på fig. 4.
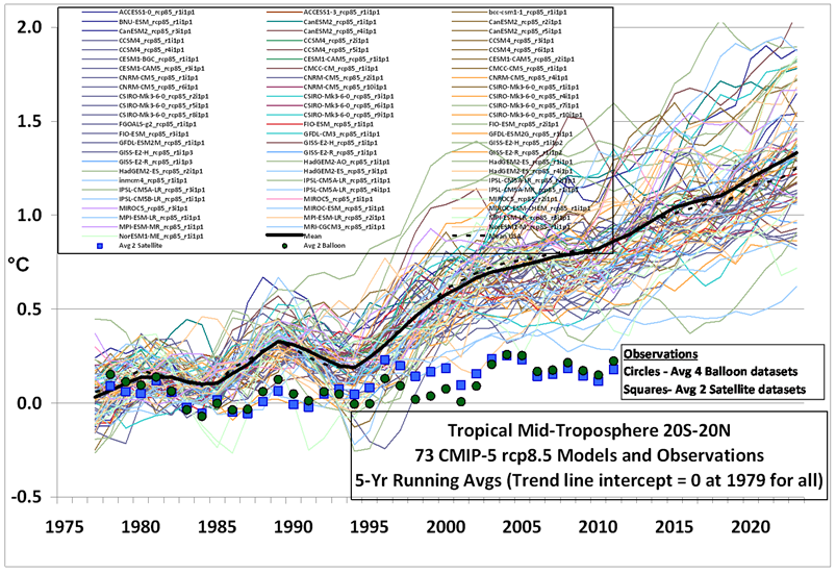
Nu kan jo højst én af disse modeller være korrekt, og det er meget sandsynligt, at ingen af dem er det. Hvis det her drejede sig om en virkelig videnskabelig proces, ville de varmeste to tredjedele af modellerne blive kasseret af IPCC, og de videre studier skulle så fokuseres på de modeller, der ligger tættest på observationerne. Men det gør IPCC ikke af en række grunde.
For det første ville der blive dyb forargelse inden for klimavidenskaben, især fra de kasserede holds side pga. deres efterfølgende tab af bevillinger. Og, mere vigtigt, den påståede 97 %-konsensus ville fordampe på stedet.
For det andet, hvis man kasserede de varmeste modeller, ville forudsigelsen for år 2100 blive en opvarmning på ca. 1,5 oC, og så er der jo ikke nogen panik, og hele forretningen går i stå.
Så hvordan skulle IPCC håndtere dette brede felt af forudsigelser?
Man kan ikke forbedre nøjagtigheden af nonsens ved at tage gennemsnittet af den.
En alternativ metode
Ophavet til klimamodellerne hævder, at det er umuligt at få en overensstemmelse med de målte data, uden at man tager påvirkningen fra CO2 med. Det er muligvis tilfældet med den fremgangsmåde, der her er beskrevet, med de mange tilnærmelser og så en justering af modellen udelukkende efter den globale overfladetemperatur, mens man ignorerer f.eks. temperaturer længere oppe i atmosfæren. Imidlertid har analytiske modeller (i modsætning til de numeriske klimamodeller) opnået overensstemmelser uden at tage CO2 med i betragtning. Disse modeller er baseret udelukkende på historiske svingninger i klimaet og bygger på matematiske metoder.
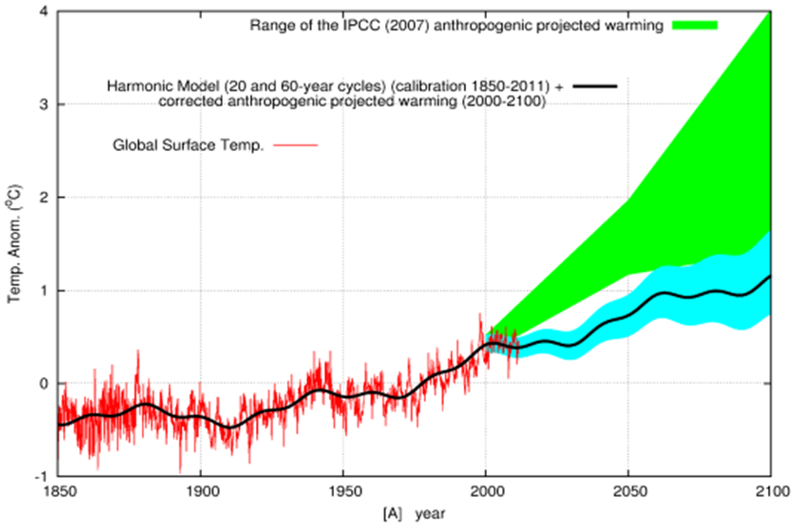
Fig. 5 viser en sammenligning mellem IPCC’s forudsigelser og en fremskrivning fra blot en enkelt matematisk model, der ikke afhænger af CO2-opvarmning. Her kan man få kurven til at stemme overens med de målte data og f.eks. er varmepausen i starten af årtusindet med, hvilket IPCC’s klimamodeller aldrig når frem til. Formålet med dette eksempel er ikke at hævde, at denne model er mere præcis, det er blot endnu en model, men i stedet kan vi forkaste myten om, at der ikke er nogen måde, hvorpå man kan simulere virkeligheden uden at bruge menneskeskabt CO2-påvirkning. Vi ser også, at det er muligt at forklare ændringerne i temperaturen som et resultat af naturlige svingninger som den dominerende årsag.
Kommentarer til ovenstående. Forfatteren har nok ikke helt ret i at klimamodellerne i nutiden er tvunget til at operere med så store celler som 100 x 100 km. Grænsen går i dag nok nærmere 10 x 10 km. Men det ændrer ikke alverdens ved konklusionerne, der er stadigvæk en række meteorologiske fænomener, f.eks. omkring skydannelsen, som modeller ikke kan regne på direkte.
Ideen med at bruge analytiske modeller ligger ikke helt fremmed for IPCC, der i den seneste rapport udtrykker sin tvivl over for de meget varme klimamodeller og i stedet lægger sig på tal, der delvist er baseret på ”alternative” beregningsmetoder, og som giver en mindre opvarmning ved en fordobling af atmosfærens CO2-indhold.
Hvor længe kan forestillingen med de store altopslugende klimamodeller mon fortsætte uhindret?





Tak for at vi endnu en gang bliver gjort opmærksom på, at (den første) fordobling af atmosfærens CO2 højest kan give en temperaturstigning på ca 0,5 grader. Skrækscenariet med de efterfølgende 3-4 grader skyldes frygt for mere vanddamp i den øvre atmosfære. Men målinger siden 1945 viser jo, at vandindholdet er faldet med ca. 10%! Det ved IPCC og deres venner selvfølgeligt godt, men gryden skal holdes i kog – for enhver pris.
Det skrev Frank Lansner mere om i sit indlæg:
https://klimarealisme.dk/2019/06/02/vand-vand-vand-positive-water-feedbacks/