
De store globale temperaturkurver, f.eks. HadCRUT eller Berkeley bruger som grundlag en database, der kaldes GHCN (Global Historical Climatology Network) ”Det globale historiske klima-netværk”, der udgiver månedlige temperaturdata fra et meget stort antal målestationer over hele Verden.
Data fra en enkelt målestation er ikke altid så pålidelige, de kan springe meget, og de kan påvirkes af ydre faktorer, der ikke har så meget med klimaet at gøre. Store spring kan f.eks. være resultatet af, at stationen er flyttet til en ny plads, eller at den har fået nye instrumenter af en anden type. Sådanne oplysninger er i mange tilfælde til rådighed, hvor man f.eks. ved præcist, hvornår det gamle kviksølvtermometer blev afløst af et elektronisk. Men for mange andre stationer er disse oplysninger ikke kendt, i hvert fald ikke for GHCN’s ophavsfolk, se fig. 1.
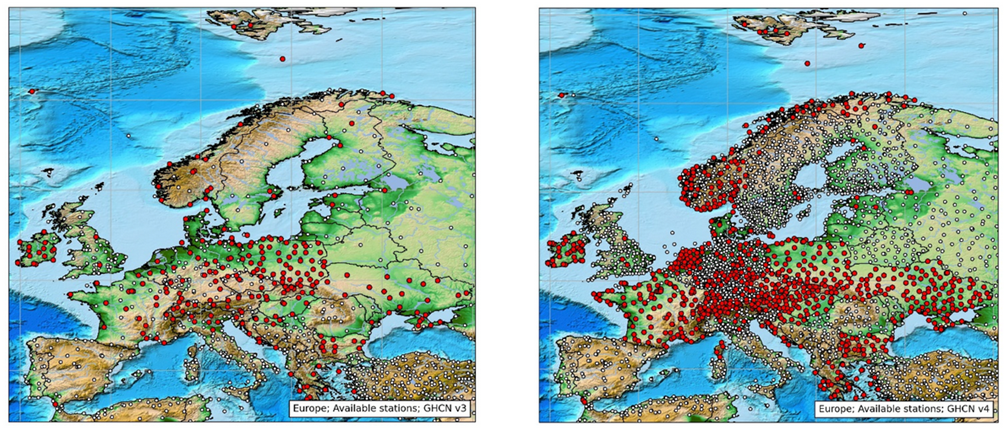
Af ydre faktorer er det ikke mindst byvarmeø-effekten, der spøger, stationerne er over årene blevet omgivet af flere og flere huse, veje, biler og andre varmeafgivende aktiviteter.
I stedet for møjsommeligt at forsøge at ”rette” stationernes målinger, har man været på udgik efter systemer, der kunne gøre det automatisk. Her er man nået frem til en ”Parvis Homogeniserings-Algoritme”, PHA (Pairwise Homogenization Algorithm). Den har været i brug i de seneste ca. 12 år.
Willie Soon og hans folk har nu underkastet denne metode et nærmere eftersyn og skrevet en lang og meget grundig artikel derom. Forfatterne her erklærer sig helt enige i, at homogeniseringen er nødvendig for at undgå store udsving, der ikke har så meget med klimaet at gøre. Men de må konkludere, at PHA og brugen af den lader en del tilbage at ønske.
PHA bruges i nogle perioder dagligt på temperaturkurverne, så der er mange opdateringer for hver station, og Soon og hans folk har omhyggeligt opsamlet de data dag for dag for at underkaste dem nærmere analyser. Grundlæggende virker PHA ved at kigge efter store spring i temperaturmålingerne, og når de finder et, vil de så inddrage nabostationernes målinger og bruge et gennemsnit af disse i stedet for den fra stationen med springet.
På papiret ser det ud til at være en rimelig metode; man får mere naturlige og troværdige tal. Imidlertid måtte forskerne her konstatere, at PHA påviste og rettede spring mange steder på kurverne, men at det fra den ene dag til den næste ikke var de samme steder, hvorimod nye kom til. Hvad værre var, metoden fangede ikke nødvendigvis de spring, der burde være et resultat af en fysisk ændring af stationen, som nævnt ovenfor, se fig. 2. I stedet foretog den homogeniseringer til andre tider, hvor der ikke var nogen ydre forklaring.
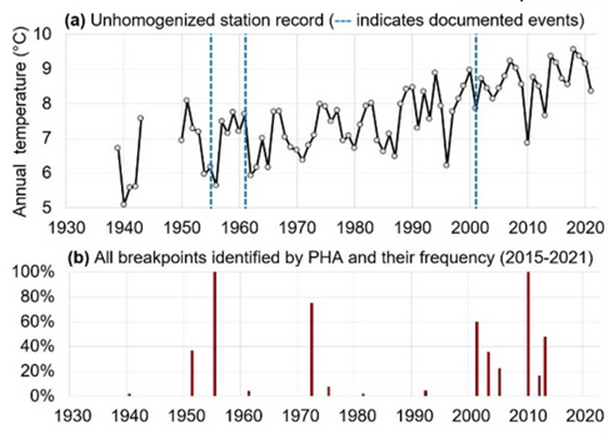
Endvidere har det vist sig, at homogeniseringen ikke har elimineret de skævvredne resultater af byvarmeø-effekten. Tværtimod har man mange steder kunnet påvise, at stationer på landet med lavere temperaturer, blev justeret op ved at bruge gennemsnittet af nærliggende stationer, der var ramt af byvarmen.
Det er en god men svært tilgængelig artikel. Man kan vel dog nok tillade sig at slå fast, at begrebet ”den globale temperatur” er en svær størrelse at håndtere – og det er flot, at IPCC kan fastsætte opvarmningen med to betydende cifre efter kommaet (”1,07 grader”). Det har vist ikke noget med virkeligheden at gøre.






